


How combining OCR and large language models eliminates template maintenance and unlocks higher automation rates across your entire supplier base
Ask any AP team how much time they spend on invoice exceptions, and the answer is almost always more than it should be. Ask them why, and the answer almost always comes back to the same root cause: the documents coming in don’t match the system’s expectations.
✨ On average monthly our platform transacts 23% of documents like the ones described above.
Template maintenance is not a one-time cost. It is a recurring tax on AP productivity that grows with your supplier base. And it creates a ceiling on automation: the more diverse your suppliers, the harder it is to keep templates current, and the more exceptions land in human queues.
There is also a second problem that often goes unspoken. Structured EDI connections are the gold standard for invoice exchange, but not every supplier has the technical capability or the resources to set one up. Smaller sellers typically send invoices as PDFs or scanned documents, and under template-based systems, that means either manual processing or an integration project nobody has budget for. AI Document Intelligence changes that equation. By handling unstructured and semi-structured documents intelligently, it makes the network more accessible to the long tail of suppliers who transact via PDF, without requiring them to invest in EDI and without requiring buyers to build and maintain templates for each one.
That is the problem AI Document Intelligent Extraction and Enrichment is built to remove: on both sides of the transaction.
What AI Document Intelligence actually does
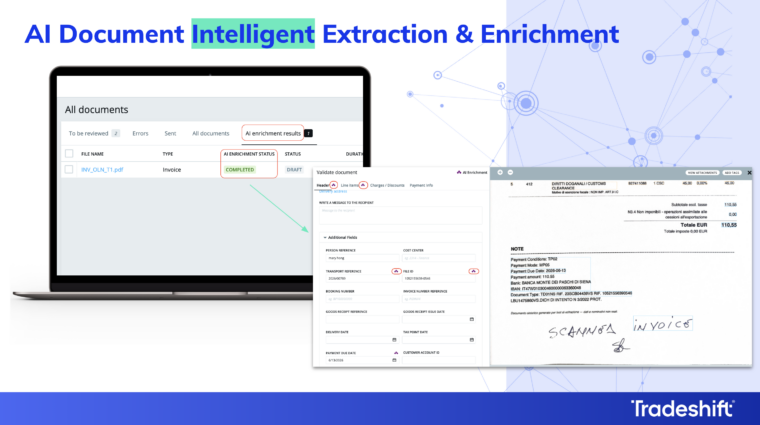
At the core of AI Document Intelligent Extraction and Enrichment is a two-layer approach to reading invoices. Advanced OCR powered by AWS Textract handles the visual interpretation of the document, accurately identifying text across native PDFs, image-based files, and scanned documents alike. Large Language Models then take that raw extraction and do something template-based systems cannot: they interpret context, infer field meaning, and structure the data correctly without needing a predefined map of the document.
The result is that the system does not need to have seen a supplier’s invoice format before to extract it accurately. It reads, reasons, and structures, the same way a trained human reviewer would, but at processing speed and at scale.
✨ Our current average data extraction accuracy rate is above 95%, measured across native PDFs and image-based PDF documents. At enterprise volumes, that accuracy translates directly into fewer exceptions, less manual review, and more invoices flowing straight through to matching without human intervention.
Three things this changes for AP teams
Template maintenance becomes a relic.
The ongoing cost of managing fixed PDF templates, updating them when suppliers change formats, creating new ones for onboarding, troubleshooting extraction failures, disappears. The AI adapts to the document rather than requiring the document to conform to a template.
Automation rates go up, and stay up.
Because the extraction engine adapts intelligently to diverse invoice layouts, automation does not degrade as your supplier base grows or diversifies. Invoices that would previously have landed in exception queues because they did not match a known template now process straight through.
The architecture scales with the business.
Legacy extraction systems tend to become more brittle over time as workarounds accumulate and edge cases multiply. AI Document Intelligence is built on a flexible foundation that handles enterprise-grade volume and global supplier diversity, and that can evolve as document types and formats change, without requiring a rebuild of the underlying logic.
Built for global supplier diversity
One of the things that makes invoice extraction genuinely hard at enterprise scale is not just volume; it is the combination of volume and variety. A global AP operation receives invoices from suppliers across dozens of countries, each with different regulatory formatting requirements, different languages, different layouts, and different levels of document quality.
Template-based systems manage this through proliferation: more templates, more maintenance, more exceptions when templates fall behind. AI Document Intelligence manages it through adaptability. The same extraction engine that reads a clean native PDF from a large European supplier also reads a scanned, image-based invoice from a supplier in an emerging market, without needing separate configuration for each.
This is particularly relevant as e-invoicing mandates expand globally and the variety of structured and semi-structured invoice formats your platform needs to handle continues to grow.
What we are hearing from customers in Early Access
AI Document Intelligent Extraction and Enrichment was opened to Early Access customers as part of the Spring Release 2026. Since then, we have run demonstrations and worked with customers across a range of AP environments, from high-volume shared services operations to teams managing complex multi-entity supplier bases.
✨ During the Early Access programme we engaged with 7 large enterprise, multi-country customers activating in diverse industries from beauty to commercial transportation and logistics to consumer goods and manufacturing.
The pattern that comes up most consistently is validation: the capability addresses a pain point that teams have been living with for years, and which they had largely accepted as an unavoidable cost of doing business. The conversation tends to shift quickly from “what does this do” to “how do we get started.”
Several themes have emerged across those conversations. Teams processing large volumes of invoices from a single high-value supplier have found that the ability to resolve customer-specific extraction requirements through custom prompts, without building or maintaining a dedicated template, removes a significant ongoing operational burden. Others have described AI Document Intelligence as solving a core digitization problem that had been blocking broader automation progress: once the extraction layer becomes reliable and adaptable, the rest of the AP workflow can be automated with confidence. And for teams that had previously tested earlier versions of the extraction capability, the improvement in accuracy when retesting the same invoice sets has been the clearest signal that the underlying technology has moved meaningfully forward.
What connects these responses is not enthusiasm for the technology itself, but recognition that it addresses something real. AP teams across industries and geographies share the same underlying problem: invoice formats vary, supplier bases are diverse, and template-based systems create a maintenance burden that limits how far automation can actually go. This is the problem AI Document Intelligence is built to solve.
The bigger picture: from extraction to autonomous processing
AI Document Intelligence is one component in a broader shift toward fully autonomous AP. As Raphael Bres outlined in his 2026 vision for agentic AI at Tradeshift, the direction of travel is clear: finance teams will stop managing processes and start managing outcomes.
Extraction is where that journey starts. If the document does not get read accurately, nothing that follows can be fully automated. Getting this right is the foundation on which higher-order automation, matching, coding, approval routing, and eventually autonomous resolution, all depend.
On the roadmap, the AI Document Supervisor will take this further still: a context-aware orchestration agent that spawns specialized extraction agents based on document type and complexity, adapting its approach dynamically rather than applying a single extraction model to every document.
Combined with Ada 3.0 for autonomous resolution, AskAda for Buyers for conversational AP triage, and the agentic AI infrastructure already in production via the Tradeshift MCP Server, the trajectory is toward an AP workflow where the platform handles the bulk of execution and your team focuses on judgment.
Join the Early Access Program
AI Document Intelligent Extraction and Enrichment is currently available in Early Access. If your team processes significant volumes of PDF, native, or image-based invoices and is looking to reduce template maintenance overhead and increase straight-through processing rates, this is worth exploring.
Join the Early Access Program
For product feedback or questions about AI Document Intelligence, reach out to your Tradeshift Customer Success Manager.